はじめに:言語は「感覚」ではなく「データ」で見る時代へ
「この表現って自然なのか?」
「どの言葉がよく使われるのか?」
これまで言語の研究は、専門家の直感や経験に頼る部分が大きいものでした。しかし現在では、大量の実際の言語データを使って分析する「コーパス言語学」というアプローチが主流になりつつあります。
この記事では、コーパス言語学について以下の観点から整理します。
- 定義と目的
- 歴史的な発展
- 利点と制約
コーパス言語学とは何か


コーパス言語学とは、
実際に使われた言語データ(コーパス)をもとに、言語の特徴を分析する学問分野です。
ここでいうコーパスとは、以下のような「現実の言語」を集めたデータです。
- 書籍・新聞・論文
- 会話データ
- SNSやブログ
- ビジネス文書
コーパス言語学の目的
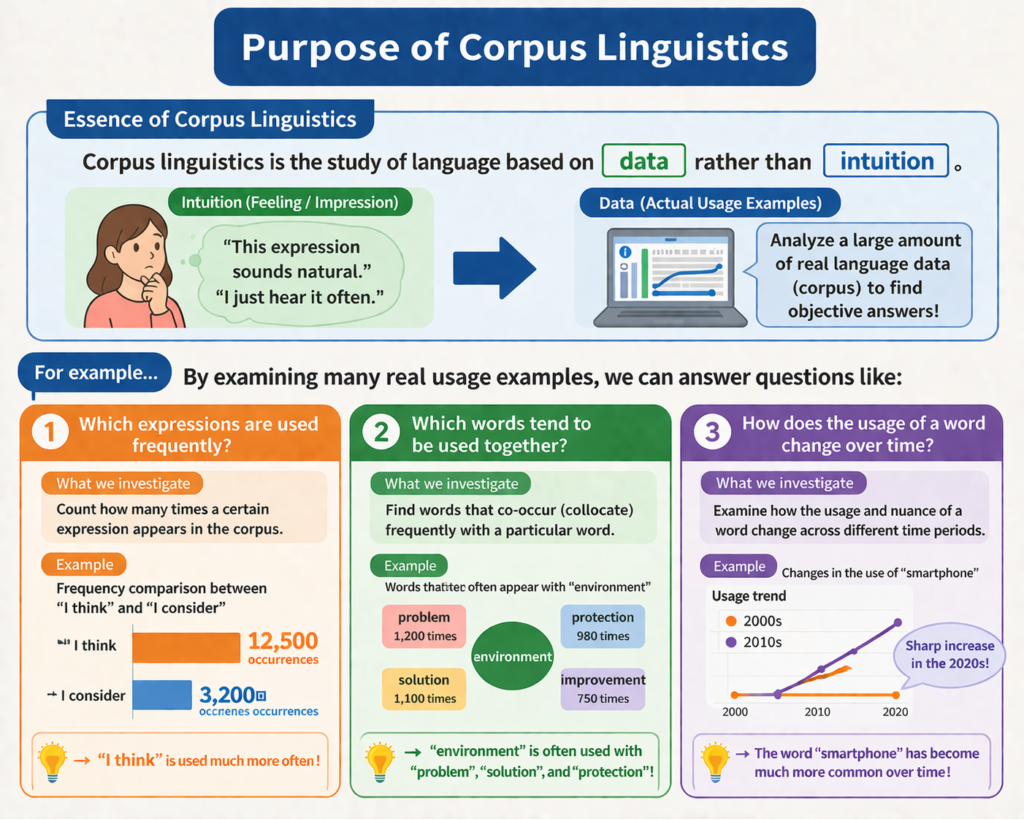
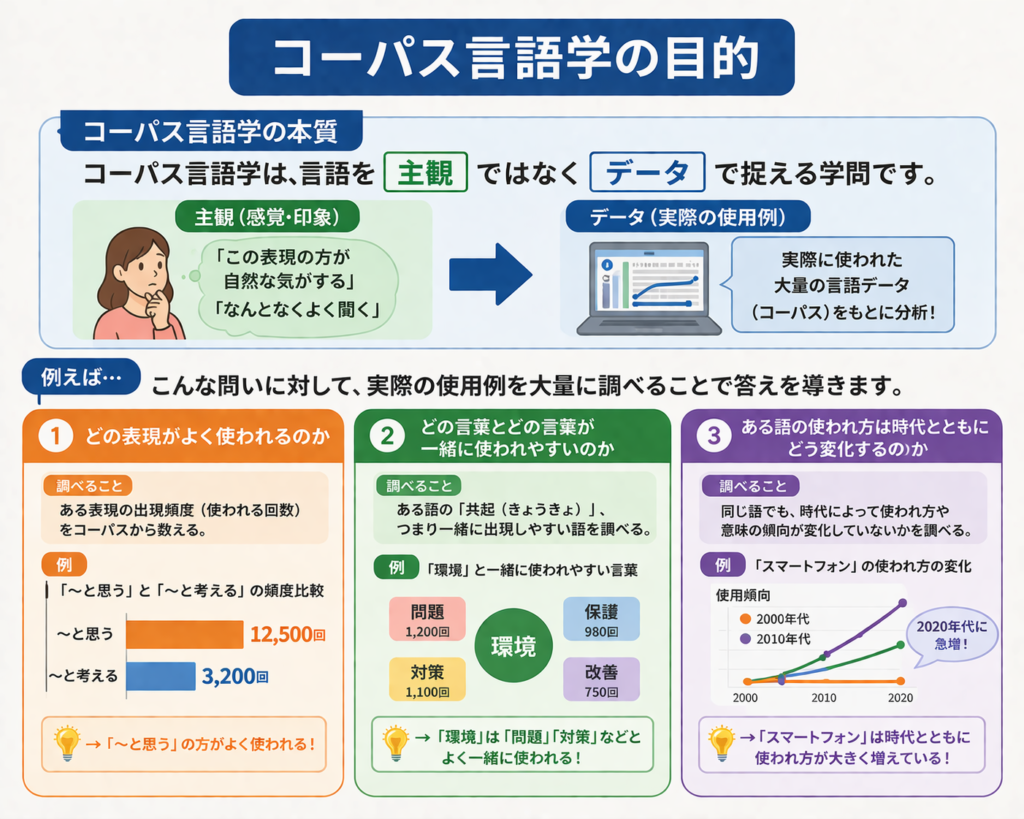
コーパス言語学の本質は、
👉 言語を「主観」ではなく「データ」で捉えることです。
例えば:
- どの表現がよく使われるのか
- どの言葉とどの言葉が一緒に使われやすいのか
- ある語の使われ方は時代とともにどう変化するのか
こうした問いに対して、実際の使用例を大量に調べることで答えを導きます。
直感からデータへ
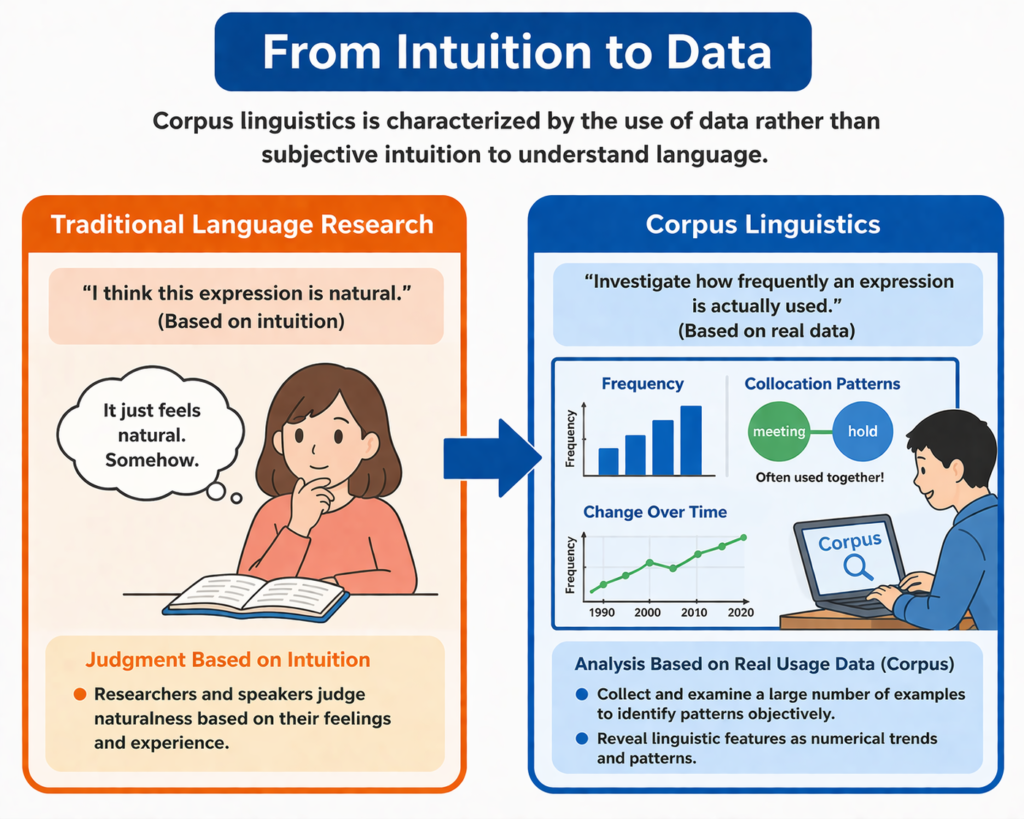
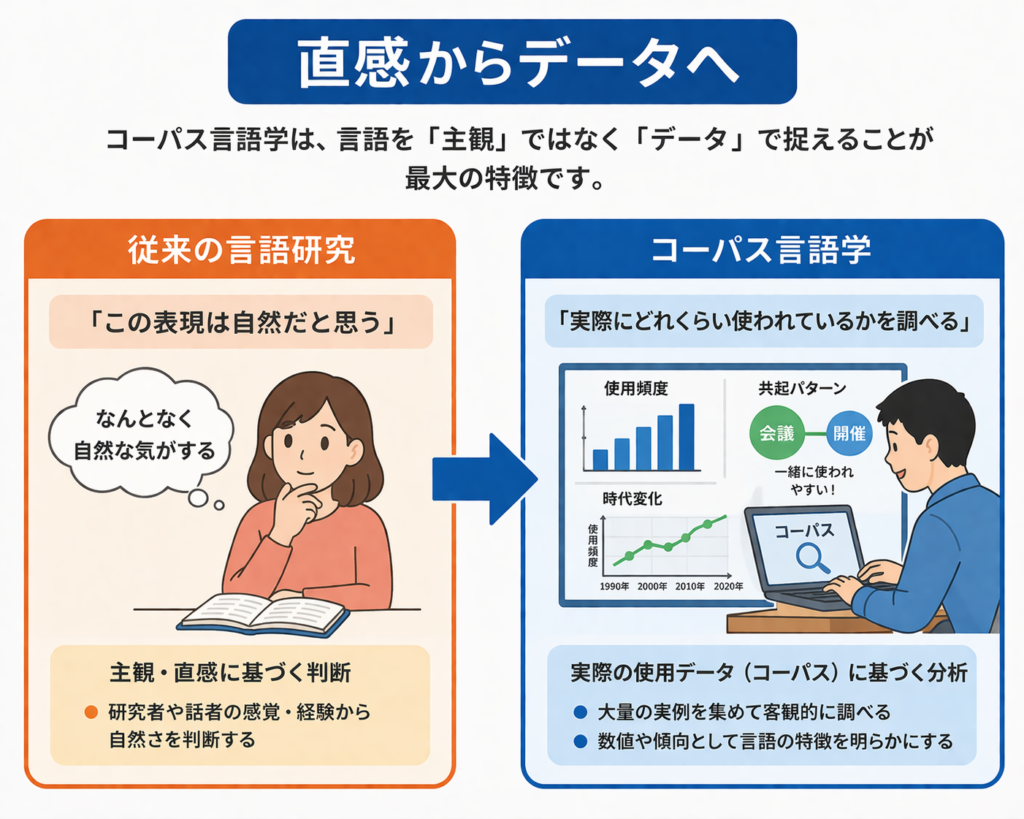
従来の言語研究:
「この表現は自然だと思う」
コーパス言語学:
「実際にどれくらい使われているかを調べる」
この違いが、コーパス言語学の最大の特徴です。
コーパス言語学の歴史と発展

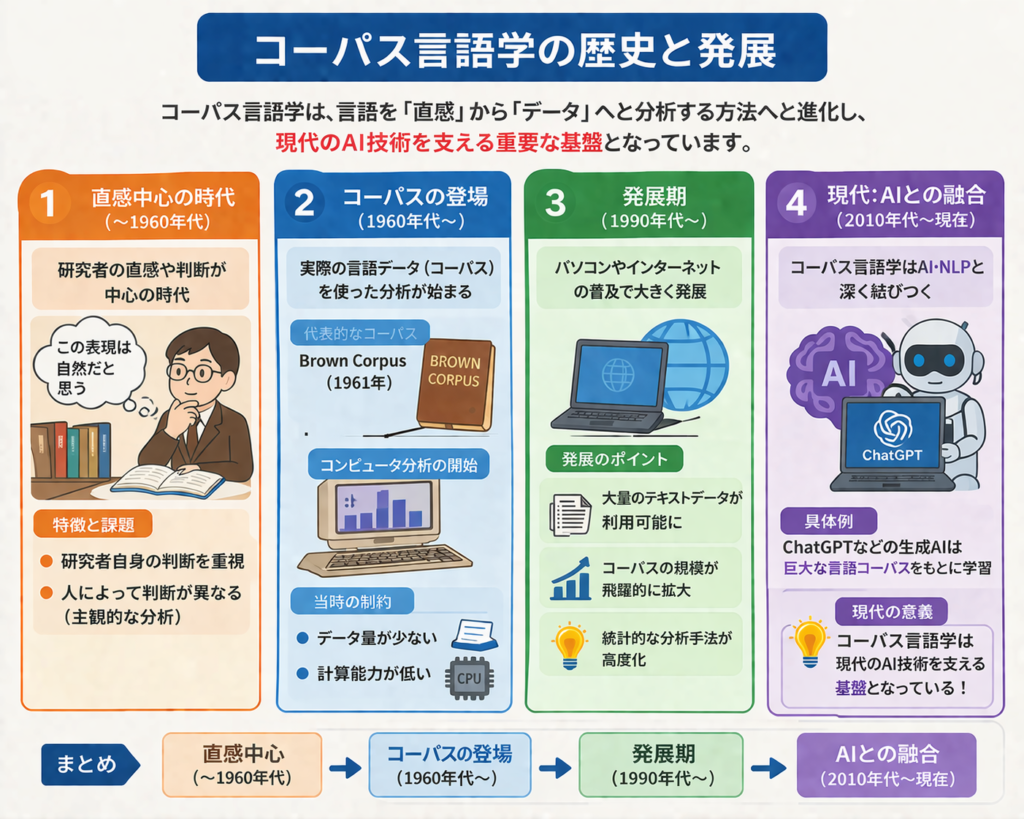
1. 直感中心の時代(〜1960年代)
初期の言語学では、研究者自身の判断が重要視されていました。
しかし、この方法には「人によって判断が異なる」という問題がありました。
2. コーパスの登場(1960年代〜)
1960年代には、代表的なコーパスである Brown Corpus が作られ、コンピュータを使った分析が始まります。
ただし当時は、
- データ量が少ない
- 計算能力が低い
といった制約がありました。
3. 発展期(1990年代〜)
パソコンやインターネットの普及により、大量のテキストデータが利用可能になります。
この時期から、コーパス言語学は一気に発展しました。
4. 現代:AIとの融合
現在では、コーパス言語学は自然言語処理(NLP)やAIと深く結びついています。
たとえば、
ChatGPT のような生成AIも、巨大な言語データ(コーパス)をもとに学習しています。
つまり、コーパス言語学は
👉 現代のAI技術を支える基盤とも言えます。
コーパスを用いた言語研究の利点
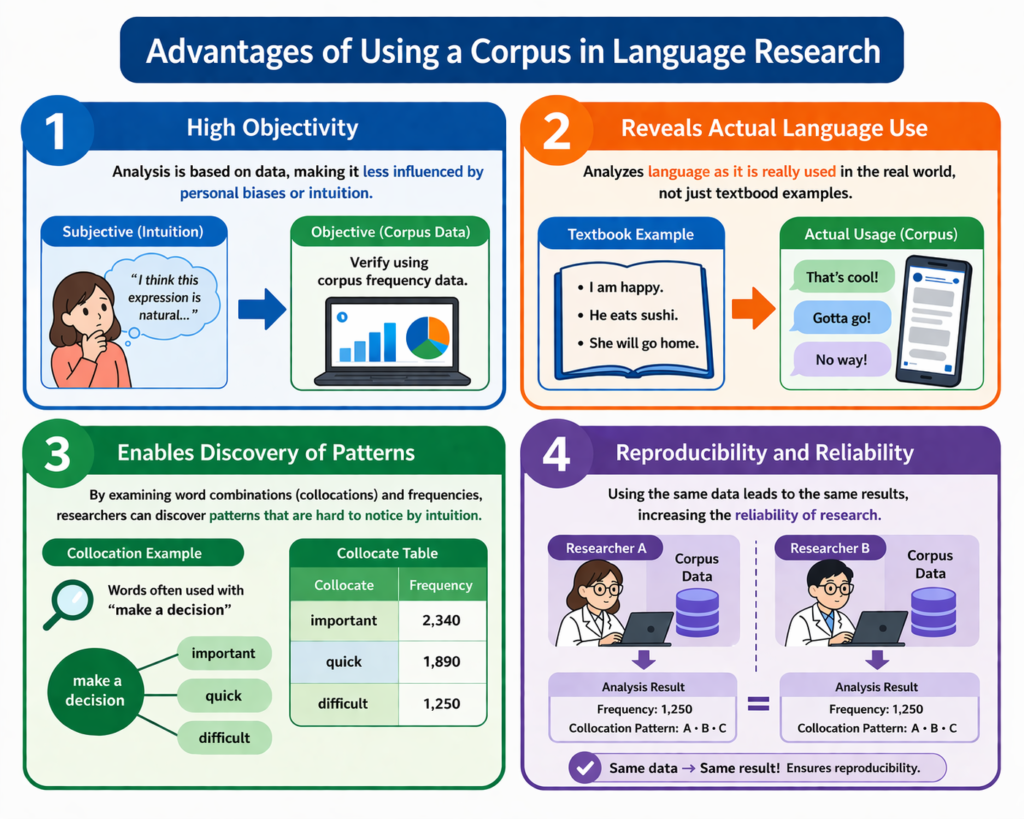
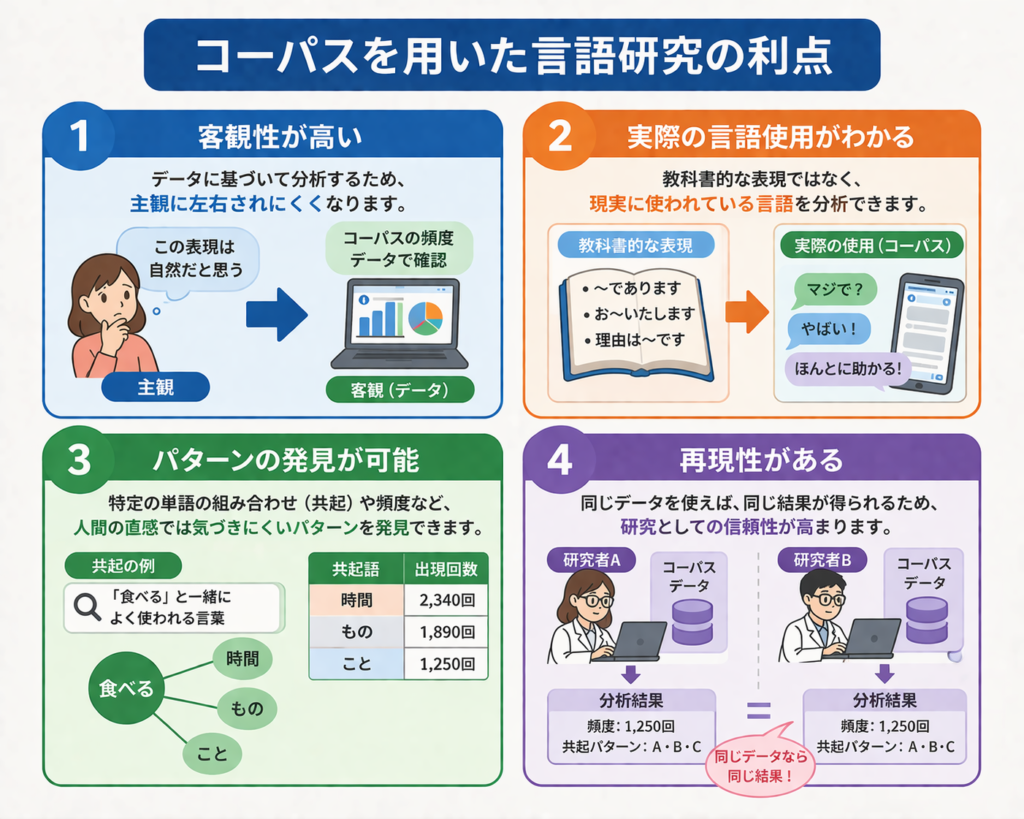
1. 客観性が高い
データに基づいて分析するため、主観に左右されにくくなります。
2. 実際の言語使用がわかる
教科書的な表現ではなく、現実に使われている言語を分析できます。
3. パターンの発見が可能
特定の単語の組み合わせ(共起)や頻度など、
人間の直感では気づきにくいパターンを発見できます。
4. 再現性がある
同じデータを使えば、同じ結果が得られるため、
研究としての信頼性が高まります。
コーパス言語学の制約と課題

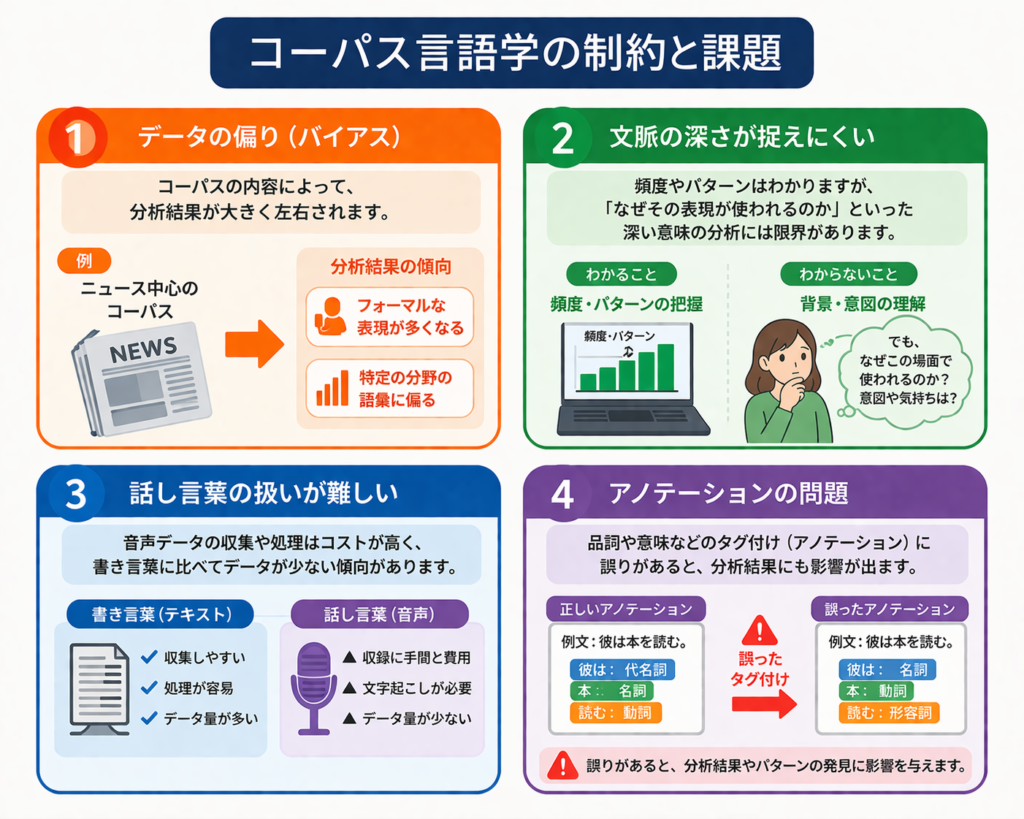
1. データの偏り(バイアス)
コーパスの内容によって、分析結果が大きく左右されます。
例:ニュース中心のコーパス → フォーマルな表現が多くなる
2. 文脈の深さが捉えにくい
頻度やパターンはわかりますが、
「なぜその表現が使われるのか」といった深い意味の分析には限界があります。
3. 話し言葉の扱いが難しい
音声データの収集や処理はコストが高く、
書き言葉に比べてデータが少ない傾向があります。
4. アノテーションの問題
品詞や意味などのタグ付け(アノテーション)に誤りがあると、分析結果にも影響が出ます。
まとめ:コーパス言語学の本質
コーパス言語学は、
👉 言語を「データとして扱う」学問です。
その特徴は以下の通りです。
- 主観ではなく実証に基づく
- 実際の言語使用を重視する
- AI・自然言語処理の基盤となる
一方で、
- データの偏り
- 文脈理解の限界
といった課題も存在します。
おわりに:言語研究の新しい視点
言語は「正しいかどうか」だけでなく、
「実際にどう使われているか」を見ることが重要です。
コーパス言語学は、その視点を私たちに与えてくれる分野です。
そしてこの考え方は、教育・AI・ビジネスなど、
さまざまな領域で今後ますます重要になっていくでしょう。
